I was shocked by the performance of the major RDBMS engines for such simple calculations over what were not that many rows of data. The combination of points and number of joins required to the different polygon columns resulted in a processing time >24hours for a daily refresh. Totally unacceptable but ‘as designed’ when queried with the provider of the Microsoft Fast Track architecture. The result on that site was to defer the computation to ArcGIS and simply consume the output CSV.
I spent a number of months investigating how the database engines process spatial queries and discovered a way to supercharge them by refactoring the spatial data into a format that is easier to consume by the database engine. I’ve successfully used this on a number of projects while waiting (and hoping) for the database providers to improve their solution so I can go back to using the features out of the box. Unfortunately this hasn’t happened, and when I recompiled the solution for SQL Server 2016 and tested it I found that while the base performance had improved, so had Simplify Spatial and it is is still many times faster. So I’ve decided to release it for all.
The suite of libraries is available from the Downloads tab.
What follows is an excerpt from a presentation from 2012
Results
| Test Case | SQL Server (2012) | PostGRES | Oracle | |||
|---|---|---|---|---|---|---|
Original | Optimised | Original | Optimised | Original | Optimised | |
| Alaska (34k points returned) | 40 sec | 1.2 sec | 2.8 sec | 0.4 sec | 10.8 sec | 2.2 sec |
| Colorado (49k points returned) | 21 sec | 1.8 sec | 2.2 sec | 0.8 sec | 5 sec | 2.1 sec |
| C% (190k points returned) | 2:02 min | 5.8 sec | 12 sec | 2.9 sec | 1:10 min | 6.5 sec |
| All (2.1m points returned) | 1:14:58 hr | 48 sec | 5:30 min | 34 sec | 50:26 min | 1:20 min |
The following source data was used for the test cases:
Polygons - the 2012 TIGER/Line Shapefiles for the polygon data http://www.census.gov/cgi-bin/geo/shapefiles2012/main
Points - main geonames table for the US http://download.geonames.org/export/dump/US.zip
The test cases were performed on the following RDBMSes on a W7 x64 machine with a quad core CPU and 8gig of ram.
| SQL Server 2012 (Microsoft SQL Server 2012 (SP1) - 11.0.3373.0 (X64)) |
| PostGRES 9.2 (x64) with PostGIS 2.0 v2.0.3 |
| Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production |
The data was imported into the above DBs as geometry and the relevant spatial indexes applied.
I ran the polygon splitting function across the US States table on the SQL Server instance and persisted it in a new physical table. This table was left as an unindexed heap. I then exported this table to the Oracle and PostGRES databases.
The tests involve running a set of simple intersection queries between the geonames US landmark point data and both the original indexed US States table and the simplified polygons in the heap.
All queries were of the form
SELECT count(*)
FROM <US_state_table> t1
INNER JOIN <geonames_landmark_table> t2
ON <Intersection between t2.geom and t1.geom is true>
This limited the test to the internal processing of the spatial join and removed any overhead from parsing/displaying large amounts of data in the query tool.
Test Cases
The geonames landmark data was joined against the following sets of polygon data.Alaska
14033 vertices. Multi-polygon with 50 individual geometries.Purpose: Test performance of MultiPolygon geometry with complex shape and large gaps between individual geometries.

Figure 4 Original

Figure 5 Simplified. 60 individual polygons.
Colorado
8110 vertices. Single polygonPurpose: Test performance of single geometry rectangular polygon

Figure 6 Original

Figure 7 Simpified. 16 individual polygons
C% Filter
Includes Colorado, California, Connecticut and Commonwealth of Northern Mariana Islands (not shown, too far left).Vertex counts range from 818 to 11131 for each of the geometry objects.
Purpose: Test performance of over a small set of simple and complex polygons.

Figure 8 Original

Figure 9 Simplified. 51 individual polygons
All States
56 geometries ranging from 400 to 44000 vertices. Combination of single and multi-polygon geometries.Purpose: Large scale test
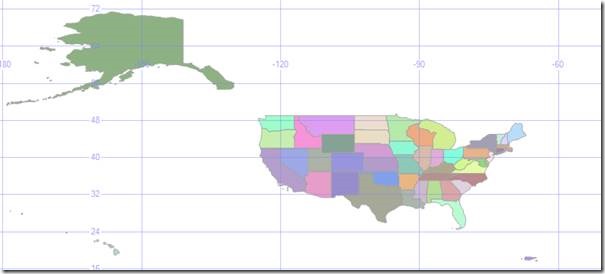
Figure 10 Original
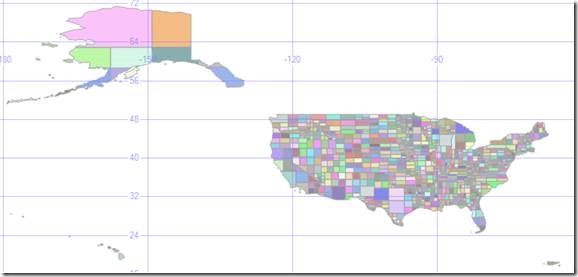
Figure 11 Simplified. 2226 individual polygons.
Query Times
| Test Case | SQL Server (2012) | PostGRES | Oracle | |||
|---|---|---|---|---|---|---|
Original | Optimised | Original | Optimised | Original | Optimised | |
| Alaska (34k points returned) | 40 sec | 1.2 sec | 2.8 sec | 0.4 sec | 10.8 sec | 2.2 sec |
| Colorado (49k points returned) | 21 sec | 1.8 sec | 2.2 sec | 0.8 sec | 5 sec | 2.1 sec |
| C% (190k points returned) | 2:02 min | 5.8 sec | 12 sec | 2.9 sec | 1:10 min | 6.5 sec |
| All (2.1m points returned) | 1:14:58 hr | 48 sec | 5:30 min | 34 sec | 50:26 min | 1:20 min |
Every query I ran against the simplified polygons was magnitudes faster than and just as accurate as the resultset against the original state geometry! The returns diminished when the number of individual polygon slices approached the number of geometry points.
SQL Server 2016 (updated)
The above test cases were re-run on SQL Server 2016 (SP1 CU3) running on a D12_V2 VM on azure (4 core 28GB RAM).| Test Case | SQL Server (2016) | |||
|---|---|---|---|---|
Original(1st run) | Optimised (1st run) | Original (2nd+ run) | Optimised (2nd + run) | |
| Alaska (34k points returned) | 21 sec | 3.2 sec | 13.9 sec | 1 sec |
| Colorado (49k points returned) | 13.6 sec | 9 sec | 9.3 sec | 0.8 sec |
| C% (190k points returned) | 45.3 sec | 7.6 sec | 38.3 sec | 2.9 sec |
| All (2.1m points returned) | 8:27 min | 27.1 sec | 8:24 min | 16 sec |
| The improvements in SQL Server 2016 spatial have led to performance increases in both the vanilla engine that are siginificant over the original timings, but those improvements have also led to the Simplify Spatial tools running faster as well!. The Simplify Spatial tools scale in the ‘good’ way, meaning the more complex (and slow) the query is on the vanilla engine, the greater % improvement when using the Simplify Spatial tools. | |